...
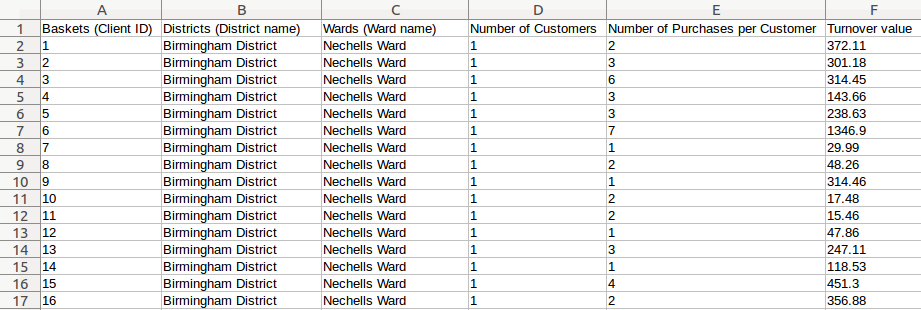
Exported file in a spreadsheet editor
![]() It is a good practice to also include the primary key in the export definition, otherwise it can lead to duplicated records in the result of the export process. The duplicated records can occur because the dataset's columns and metric values needs to be joined and if there is no primary key, then the join is performed using all available columns. And if any of the columns contains some NULL values, the join process is not able to correctly match the records, because of the NULL values inequality.
It is a good practice to also include the primary key in the export definition, otherwise it can lead to duplicated records in the result of the export process. The duplicated records can occur because the dataset's columns and metric values needs to be joined and if there is no primary key, then the join is performed using all available columns. And if any of the columns contains some NULL values, the join process is not able to correctly match the records, because of the NULL values inequality.
Let's have an example. We have a dataset of branches like this:
| branch_id | branch_name | city |
|---|---|---|
| 10 | Branch Prague | Prague |
| 20 | Branch London | London |
| 30 | Branch New York | NULL |
The correct definition of the export will look like this:
| Code Block |
|---|
"content": {
"properties": [
"branches.branch_id",
"branches.branch_name",
"branches.city"
]
} |
In this case the metric values are correctly joined based on the primary key branches.branch_id. The result will look like this:
| branch_id | branch_name | city | number_of_employees |
|---|---|---|---|
| 10 | Branch Prague | Prague | 100 |
| 20 | Branch London | London | 250 |
| 30 | Branch New York | NULL | 300 |
The incorrect definition of the export will look like this:
| Code Block |
|---|
"content": {
"properties": [
"branches.branch_name",
"branches.city"
]
} |
In this case the metric values needs to be joined using columns branches.branch_name and branches.branch_city, because there is no primary key defined. And because the column city contains NULL value on the third row, the records are not correctly matched in the case of "Branch New York" and it results to duplicated records.
The result will look like this:
| branch_id | branch_name | city | number_of_employees |
|---|---|---|---|
| 10 | Branch Prague | Prague | 100 |
| 20 | Branch London | London | 250 |
| 30 | Branch New York | NULL | NULL |
| NULL | NULL | NULL | 300 |