A metric is an expression which describes a computation that will be performed over the project's data. Metrics are written in a custom query language, which is fairly simple and doesn't require users to know SQL. A metric written in this language is then translated to SQL by a backend service and executed as multidimensional query on data warehouse.
A metric is visualised on the map using an indicator, in which it is referenced by URL.
All properties used in metrics are dataset properties, located in dwh.ref.properties. On these properties, a set of functions can be applied. They can be nested, and the results of these functions can be combined and filtered.
Syntax
This is the simplest type of metric. It returns the sum (function_sum) of all basket amounts (property baskets.amount).
All available functions and operators are described below.
{
"name": "turnover_metric",
"type": "metric",
"content": {
"type": "function_sum",
"content": [
{
"type": "property",
"value": "baskets.amount"
}
]
}
}
_
Additional syntax examples
Important - to properly understand metrics, please see these examples below.
For a complete list of supported metrics, see the Metrics cheatsheet article.
This metric extends the metric from the first example by filtering. The filter defined in options.filterBy object filters the baskets.on_off_name property with an eq operator - so the metric computes the turnover of baskets ordered offline.
All metrics can have arbitrary number of filters.
_
Let's have a look at a more complex example. This metric computes the number of purchases per customer.
Consider this metric a fraction. On the top level, the aggregate function is function_divide, which represents a fraction bar. The numerator here is a function_count of the number of baskets, and the denominator is the count of all clients.
_
This metric computes the penetration of the market. Market penetration is computed as a number of customers, divided by the sum of the number of households. This example demonstrates the use of withoutFilters. In our view, we have defined a globalDate filter which filters the dim_dates.date_iso property. There is no way to link the dim_dates and demography_postcode datasets, yet they both appear in one metric. To evade an error of finding a non-existent join path between these datasets, we use withoutFilters on all properties of the dim_dates dataset.
Another thing to note here is the use of function_ifnull. If the result of the function_divide should be null (e.g. in case of division by zero), the result of the metric in that case will be 0.0.
This metric computes the population in areas where the turnover is greater than 10000 (given that the contents of the demography dataset are computed to the ward level).
This metric uses the inAttribute operator, which is a specific operator that allows you to filter the metric based on the result of another metric (query). This query is specified in the filterBy.query object. This functionality - filtering areas based on the result of a different query - is also available in the form of indicator filters defined in the view object.
Arrivals/departures metrics compute the number of, e.g. people which have arrived to or departed from a destination. Whether it is a country, a city, (polygon) or a shop (marker). The syntax of these two metrics is very similar. Apart from this specific syntax, a indicator.content.relations.reversedMetric must be specified in the corresponding indicator:
And vice versa for destinations_indicator.
Also, the data which these metrics work with must have a specific format - mirrored pairs with values for each source/destination node:
| id | source_country | destination_country | arrivals | departures |
|---|---|---|---|---|
| 1 | USA | Canada | 20 000 | 8 000 |
| 2 | Canada | USA | 8 000 | 20 000 |
| 3 | USA | United Kingdom | 32 000 | 18 500 |
| 4 | United Kingdom | USA | 18 500 | 32 000 |
This is a metric which uses metric variables. The resulting sum of an exposure index is simply multiplied by the value substituted in the index_variable. The variables are set in the variables filter in the view object.
Key description
content
| Key | Type | Optionality | Description | Constraints |
|---|---|---|---|---|
type | string | REQUIRED | dwh query property, dwh query function, or a number |
|
content | array | REQUIRED | array of dwh property definitions (see the | |
options | object | OPTIONAL | function options, allows to specify filters |
content.content
| Key | Type | Optionality | Description | Constraints |
|---|---|---|---|---|
id | string | OPTIONAL | choose a custom string identifier for the query property | (a-z0-9_-) |
type | string | REQUIRED | dwh query property, dwh query function, or a number |
|
value | string long decimal | REQUIRED | string identifier of a dataset property, which the function will be applied to (for string with variable name (for long or decimal value (for |
|
content.options
| Key | Type | Optionality | Description | Constraints |
|---|---|---|---|---|
aggregateBy | array | OPTIONAL | specifies datasets which the metric will be aggregated to if specified, always | [null] |
acceptAggregateBy | array | VARIES | specifies datasets which the metric is allowed to be aggregated to array of dataset names, or name prefixes (with the
|
|
dontAggregateBy | array | VARIES | specifies datasets which the metric is not allowed to be aggregated to array of dataset names, or name prefixes (with the
|
|
withoutFilters | array | VARIES | specifies dataset properties not to be explicitly joined into the final query array of dataset properties
|
|
acceptFilters | array | VARIES | specifies dataset properties to be explicitly joined into the final query array of dataset properties
|
|
filterBy | object | OPTIONAL | object specifying the filter of the metric | |
places | integer | OPTIONAL | the number of places to round the metric result to
|
Detailed options description
aggregateBy:
Specifies datasets which the metric will be aggregated to, usually some administrative unit - district, ward, etc.
So far, only null is implemented. That means, do not aggregate to any datasets. For example, we'd like to see a metric that computes the turnover share of one administrative unit, in comparison to the total turnover. Syntax of this metric would be:
acceptAggregateBy and dontAggregateBy:
Specify datasets which the metric is allowed/not allowed to be aggregated to, usually some administrative unit - district, ward, etc.
Some metrics are not computable when aggregated to certain datasets. Say we have a 3-level hierarchical administrative units - districts, wards and postcodes. But the business data is available only up to the 2nd level - wards.
When aggregating to the 3rd level (selecting the postcodes granularity), the metric would not be computable and respective indicator would show the "N/A" result. To avoid this, use acceptAggregateBy or dontAggregateBy.
Using these options, the indicator card will show an explanation of why is there no metric result.
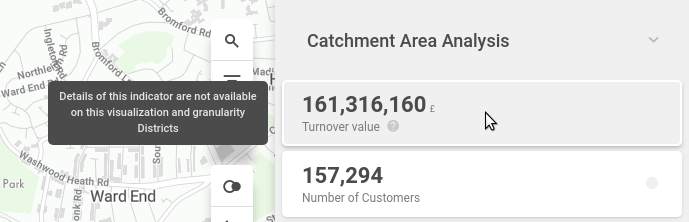
_
withoutFilters has 3 use cases:
- If the map is zoomed in on a certain level, the map window has its bounding box properties. In this case,
withoutFiltersis used to not apply the filter to the areas which are out of the current bounding box. This is a performance improvement. - If there is an strictly defined metric e.g. "total number of customers", as shown in the example below. After applying a filter, the result of this metric wouldn't make sense. So here,
withoutFiltersprevents these possible semantic issues. - In an indicator, two tables can have a relationship through a catchment area - e.g. the demography of, and the orders made in a certain county. These tables however, are not linked through foreign key, and thus cannot be explicitly joined. If we apply a filter to this indicator, using
withoutFilters, we can prevent errors of not finding the join path between orders and demography. This is more of an error evasion technique.
Both withoutFilters and acceptFilters may contain:
- specific dataset properties
"clients.client_id" - wildcard on all dataset properties
"clients.*" - multiple datasets, e.g.
"dim_dates*.*"(this would filter out all datasets from the can-dim-dates dimension) - all datasets
"*.*"
The behaviour of the acceptFilters array is the opposite of withoutFilters. Because sometimes, it is much simpler to define a list of filters to be accepted than those to be ignored.
An example can be seen above in the "Market penetration metric object syntax" code excerpt.
content.options.filterBy
filterBy is a versatile object that provides various ways of filtering the result of the metric.
| Key | Type | Optionality | Description | Constraints |
|---|---|---|---|---|
property | string | REQUIRED | identifier of a dataset property, which the filter will be applied to | {datasetName}.{datasetProperty} |
value | string long decimal boolean | VARIES | value, by which the property will be filtered this key is polymorphic - it doesn't have only one type it can also be a single value, or an array:
| |
| object | VARIES | query, by which the property will be filtered (see the
| |
operator | object | REQUIRED | the operator that will be used by the filter see the available |
filterBy examples
DWH query function list
Aggregate functions
Aggregate functions compute a single result from a set of input values.
| Identifier | Description | Example |
|---|---|---|
function_avg | arithmetic average of all input values | function_avg(42.0, 17.38, 87.2, 36.9) = 45,87 |
function_sum | sum of all input values | function_sum |
function_count | distinct count of all input values that are not null | function_count( |
function_max | maximum value | function_max |
function_min | minimum value | function_min |
function_stddev_samp | sample standard deviation of the input values | function_stddev_samp |
function_stddev_pop | population standard deviation of the input values | function_stddev_pop |
function_var_samp | sample variance of the input values | function_var_samp |
function_var_pop | population variance of the input values |
|
Window functions
Window functions provide the ability to perform calculations across sets of rows that are related to the current query row.
| Identifier | Description | Example |
|---|---|---|
| integer ranging from 1 to the argument value, dividing the partition as equally as possible |
|
function_rank | rank of the current row with gaps |
|
function_percentile | value below which a given percentage of observations in a group of observations fall |
input values sorted = (105.9, 75.2, 61.1, 42.7, 35.2, 21, 10)
|
function_row_number | a unique number for each row starting with 1. For rows that have duplicate values, numbers are arbitrary assigned. |
|
Arithmetic functions
Basic arithmetic functions.
function_plus,function_minusandfunction_multiplyaccept 2 or more argumentsfunction_divideandfunction_moduloaccept exactly 2 arguments
| Identifier | Example |
|---|---|
|
|
function_minus |
|
function_multiply |
|
function_divide | 7 / 2 = 3.5 |
function_modulo | 7 mod 2 = 1 |
Mathematical functions
Basic mathematical functions.
| Identifier | Description | Example |
|---|---|---|
function_round | a rounding function (round to specific number of places) | function_round(56.157094235, 1) = 56.2 |
Conditional functions
| Identifier | Description | Example |
|---|---|---|
| defines the default value to use if the result of aggregate function is null |
|
Filter operators list
Operators
| Identifier | Description | Example |
|---|---|---|
eq | is equal |
|
ne | negated |
|
in | in range |
|
lt | lower than |
|
lte | lower than or equal |
|
gt | greater than |
|
gte | greater than or equal |
|
isNull | is null |
|
isNotNull | is not null |
|
inAttribute | is in attribute | see the usage in a complete metric example above |
notInAttribute | is not in attribute | complementary to the inAttribute example |
Logical operators
Allow you to create advanced filters and to combine operators.
| Identifier | Description |
|---|---|
and | logical conjuction - takes at least two arguments |
or | logical disjunction - takes at least two arguments |
not | negation - takes one argument |
Visual representation
Metrics do not have a visual representation in the application.